graph TD; A[r_training] --> B[scripts]; A --> C[data]; A --> D[outputs];
Importación, Organización y Escritura de Datos
Capacitación en R
Buenas Prácticas en la Organización de Proyectos
Al comenzar un nuevo análisis, organiza tu trabajo creando un sistema estructurado de carpetas:
📁
r_training📂
scripts/(código)📂
data/(conjuntos de datos)📁
outputs/(resultados como gráficos, tablas, etc.)
Note
Usa minúsculas y guiones (-) en lugar de espacios al nombrar carpetas, archivos y objetos en R para mantener la consistencia y facilitar la gestión.
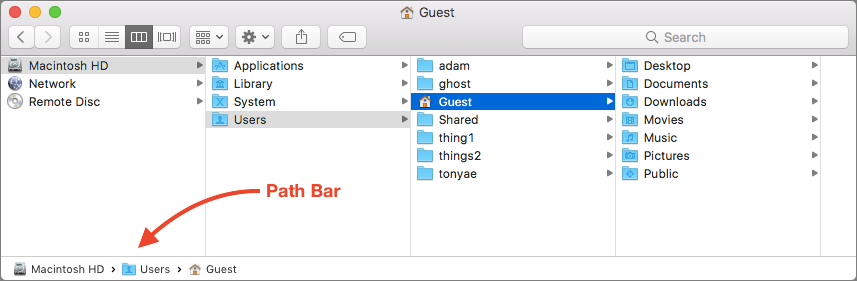
Entendiendo las Rutas de Carpetas
- Una ruta es una dirección que le dice al software dónde encontrar un archivo o carpeta en tu computadora.
Dos Tipos de Rutas:
- Ruta Absoluta:
/Users/tunombre/Desktop/r_training - Ruta Relativa:
r_training/scripts
La Ventaja de Usar Proyectos
R no sabe automáticamente dónde están tus archivos. Usar un proyecto de RStudio crea un atajo que le dice a R dónde encontrar todo, haciendo tu flujo de trabajo más fluido.
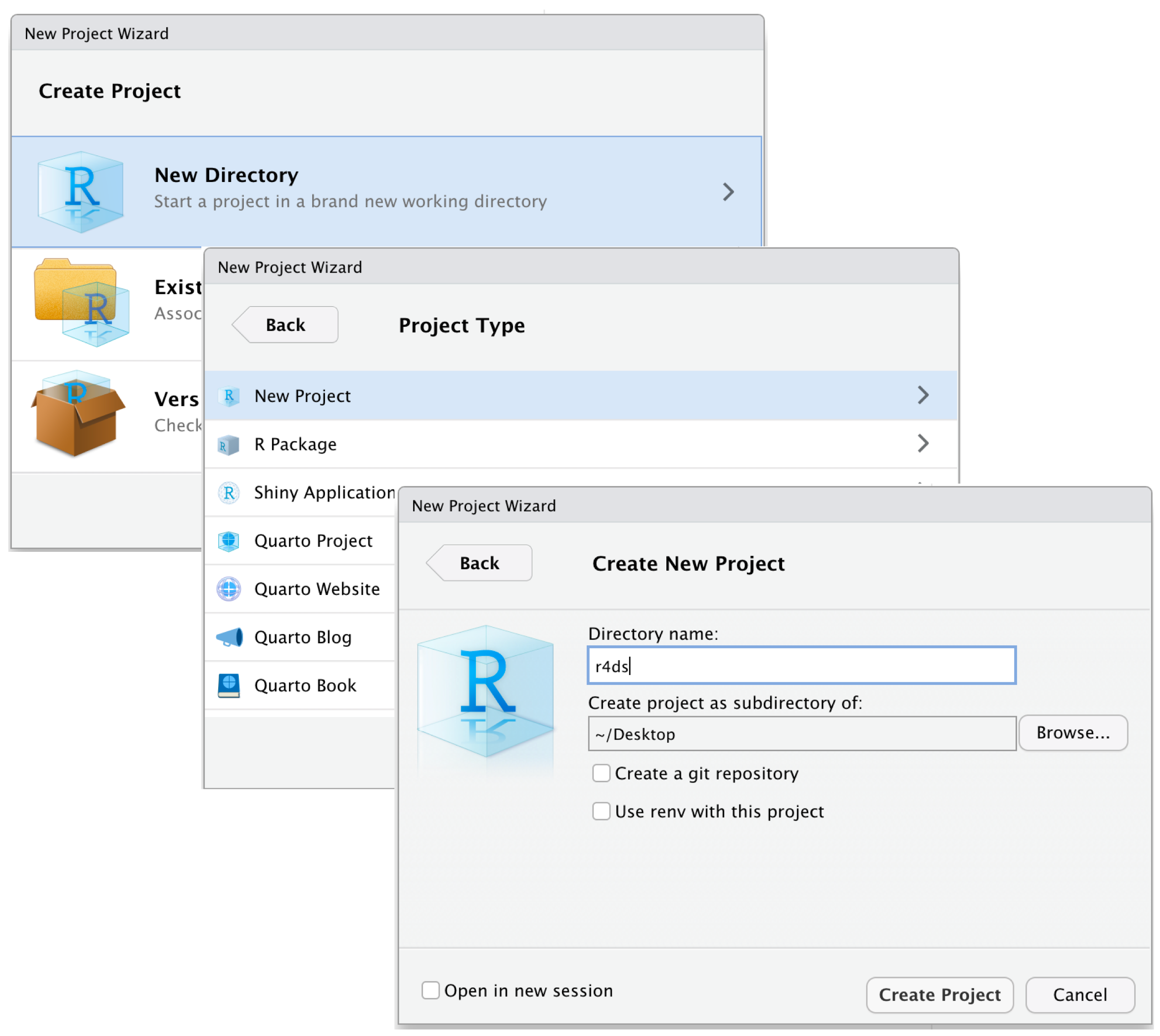
Configurando Tu Entorno
05:00 Crea una nueva Carpeta llamada
r_trainingCrea un Proyecto
- Abre RStudio.
- Ve a File > New Project > Existing Directory.
- Navega a tu carpeta
r_trainingy haz clic en Open.
- Haz clic en Create Project para finalizar.
Abre el Proyecto (Haz doble clic en el archivo para abrirlo en RStudio.)
Ejecuta este comando en la Consola de RStudio:
- Sigue las indicaciones para descomprimir los materiales en tu carpeta de proyecto.
¡Estás listo para comenzar! 🎉
Organizando la Carpeta data
graph TD; A[data] --> B[Raw]; A --> C[Intermediate]; A --> D[Final];
Raw
- Datos originales, sin tocar.
- Se recomienda respaldo para preservar la integridad.
Intermediate
- Datos formateados, renombrados y organizados.
- Listos para limpieza adicional.
Final
- Datos limpios y transformados.
- Listos para gráficos, tablas y regresiones.
Importación
Preparando Datos para R: Conceptos Generales y Mejores Prácticas
Tipos de Documentos las organizaciones dependen extensivamente de hojas de cálculo (leer)
Los formatos de datos comunes incluyen:
Hojas de cálculo (.csv, .xlsx, xls…): Estándar para datos estructurados.
DTA (.dta): Usado para datos de STATA.
Hojas de cálculo
CSV es generalmente preferible:
Más fácil de importar y procesar.
Más compatible entre diferentes sistemas y software y mucho más ligero.
Avanzado
El formato Apache Arrow está diseñado para manejar grandes conjuntos de datos de manera eficiente, haciéndolo adecuado para análisis de big data. Los archivos Arrow ofrecen operaciones de lectura/escritura más rápidas en comparación con los formatos tradicionales.
Importando Datos en R
Ejercicio 1: Importación de Datos
Puedes encontrar el ejercicio en la carpeta “Exercises/exercise_01_template.R”
10:00 Tus tareas:
Cargar paquetes usando
pacmanImportar tres conjuntos de datos:
firm_characteristics.csv(usafread)vat_declarations.dta(usaread_dta)
cit_declarations.xlsxhoja 2 (usaread_excel)
- Para cada conjunto de datos:
- Mostrar las primeras 5 filas
- Verificar nombres de columnas
- Limpiar nombres con
janitor::clean_names()
- Bonus: Asegurar que las columnas de ID de empresa tengan el mismo nombre en todos los conjuntos de datos
Ejercicio 1: Soluciones
# Cargar paquetes
packages <- c("readxl", "dplyr", "tidyverse", "data.table", "here", "haven", "janitor")
if (!require("pacman")) install.packages("pacman")
pacman::p_load(packages, character.only = TRUE, install = TRUE)
# Cargar características de empresas
dt_firms <- fread(here("Data", "Raw", "firm_characteristics.csv"))
head(dt_firms, 5)
names(dt_firms)
dt_firms <- clean_names(dt_firms)
# Cargar declaraciones de IVA
panel_vat <- read_dta(here("Data", "Raw", "vat_declarations.dta"))
head(panel_vat, 5)
names(panel_vat)
# Cargar declaraciones de impuesto de sociedades
panel_cit <- read_excel(here("Data", "Raw", "cit_declarations.xlsx"), sheet = 2)
head(panel_cit, 5)
names(panel_cit)
# Bonus: Asegurar nomenclatura consistente
panel_vat <- rename(panel_vat, firm_id = id_firm) # si es necesarioInspeccionando Datos
Inspeccionando Tus Datos: Primera Vista
- Una vez que los datos están importados, primero queremos echarles un vistazo 👀
# A tibble: 6 × 7
`Taxpayer ID` Name `Tax Filing Year` `Taxable Income` `Tax Paid` Region
<chr> <chr> <dbl> <dbl> <dbl> <chr>
1 TX001 John Doe 2020 89854 8985 North
2 TX001 John Doe 2021 65289 6528 North
3 TX001 John Doe 2022 87053 8705 North
4 TX001 John Doe 2023 58685 5868 North
5 TX002 Jane Smith 2020 97152 9715 South
6 TX002 Jane Smith 2021 62035 6203 South
# ℹ 1 more variable: `Payment Date` <dttm># A tibble: 6 × 7
`Taxpayer ID` Name `Tax Filing Year` `Taxable Income` `Tax Paid` Region
<chr> <chr> <dbl> <dbl> <dbl> <chr>
1 TX009 Olivia King 2022 91276 9127 North
2 TX009 Olivia King 2023 90487 9048 North
3 TX010 Liam Scott 2020 50776 5077 South
4 TX010 Liam Scott 2021 86257 8625 South
5 TX010 Liam Scott 2022 52659 5265 South
6 TX010 Liam Scott 2023 76665 7666 South
# ℹ 1 more variable: `Payment Date` <dttm>Note
También podrías notar que las columnas Taxpayer ID y Full Name están rodeadas de acentos graves. Esto es porque contienen espacios, lo que rompe las reglas estándar de nomenclatura de R, convirtiéndolas en nombres no sintácticos. Para referirte a estas variables en R, necesitas encerrarlas en acentos graves.
Inspeccionando Tus Datos: Dimensiones
- Verificar las dimensiones de tus datos:
Inspeccionando Tus Datos: Estructura
- Obtener nombres de columnas y examinar la estructura de datos:
[1] "Taxpayer ID" "Name" "Tax Filing Year" "Taxable Income"
[5] "Tax Paid" "Region" "Payment Date" [1] "Taxpayer ID" "Name" "Tax Filing Year" "Taxable Income"
[5] "Tax Paid" "Region" "Payment Date" tibble [40 × 7] (S3: tbl_df/tbl/data.frame)
$ Taxpayer ID : chr [1:40] "TX001" "TX001" "TX001" "TX001" ...
$ Name : chr [1:40] "John Doe" "John Doe" "John Doe" "John Doe" ...
$ Tax Filing Year: num [1:40] 2020 2021 2022 2023 2020 ...
$ Taxable Income : num [1:40] 89854 65289 87053 58685 97152 ...
$ Tax Paid : num [1:40] 8985 6528 8705 5868 9715 ...
$ Region : chr [1:40] "North" "North" "North" "North" ...
$ Payment Date : POSIXct[1:40], format: "2020-01-31" "2021-12-31" ...Inspeccionando Tus Datos: Mejor Vista de Estructura
- Obtengamos una mejor instantánea de la estructura y contenido de datos:
Rows: 40
Columns: 7
$ `Taxpayer ID` <chr> "TX001", "TX001", "TX001", "TX001", "TX002", "TX002"…
$ Name <chr> "John Doe", "John Doe", "John Doe", "John Doe", "Jan…
$ `Tax Filing Year` <dbl> 2020, 2021, 2022, 2023, 2020, 2021, 2022, 2023, 2020…
$ `Taxable Income` <dbl> 89854, 65289, 87053, 58685, 97152, 62035, 60378, 876…
$ `Tax Paid` <dbl> 8985, 6528, 8705, 5868, 9715, 6203, 6037, 8768, 9368…
$ Region <chr> "North", "North", "North", "North", "South", "South"…
$ `Payment Date` <dttm> 2020-01-31, 2021-12-31, 2022-01-31, 2023-04-30, 202…Tip
¡glimpse() es como str() pero más legible! Muestra tipos de datos, primeros valores, y se ajusta bien en tu consola.
Inspeccionando Tus Datos: Estadísticas Resumidas
- Generar estadísticas resumidas para todas las columnas:
Taxpayer ID Name Tax Filing Year Taxable Income
Length:40 Length:40 Min. :2020 Min. :50438
Class :character Class :character 1st Qu.:2021 1st Qu.:58748
Mode :character Mode :character Median :2022 Median :78590
Mean :2022 Mean :75504
3rd Qu.:2022 3rd Qu.:90287
Max. :2023 Max. :98140
Tax Paid Region Payment Date
Min. :5043 Length:40 Min. :2020-01-31 00:00:00
1st Qu.:5874 Class :character 1st Qu.:2021-04-23 06:00:00
Median :7858 Mode :character Median :2022-01-15 12:00:00
Mean :7550 Mean :2022-01-02 09:00:00
3rd Qu.:9028 3rd Qu.:2023-01-07 18:00:00
Max. :9814 Max. :2023-11-30 00:00:00 Tip
¡summary() es increíblemente útil! Para variables numéricas, muestra mínimo, máximo, media, mediana y cuartiles. Para variables de caracteres, muestra longitud y clase.
Limpiando Nombres de Columnas
- Ahora, nos aseguraremos de que nuestros nombres de variables sigan la convención snake_case 😎
- Opción 1: Renombrar columnas manualmente:
- Opción 2: Convertir automáticamente todos los nombres de columnas a snake_case usando janitor:
[1] "taxpayer_id" "name" "tax_filing_year" "taxable_income"
[5] "tax_paid" "region" "payment_date" Ejercicio 2: Inspeccionando Datos
Puedes encontrar el ejercicio en la carpeta “Exercises/exercise_02_template.R”
10:00 Tus tareas:
Usando los tres conjuntos de datos que importaste en el Ejercicio 1:
- Para
dt_firms:
- Verificar dimensiones (filas y columnas)
- Usar
glimpse()para examinar estructura - Generar estadísticas resumidas
- Para
panel_vat:
- Mostrar las primeras 10 filas
- Verificar número de empresas únicas
- Encontrar nombres de columnas
- Para
panel_cit:
- Mostrar las últimas 5 filas
- Verificar si hay valores faltantes usando
summary()
Ejercicio 2: Soluciones
# Cargar paquetes requeridos
library(dplyr)
library(data.table)
# 1. Inspeccionar dt_firms
dim(dt_firms)
glimpse(dt_firms)
summary(dt_firms)
# 2. Inspeccionar panel_vat
head(panel_vat, 10)
length(unique(panel_vat$firm_id))
names(panel_vat)
# 3. Inspeccionar panel_cit
tail(panel_cit, 5)
summary(panel_cit)Escribiendo Datos en R
Escribir en Formato .csv es (Casi) Siempre una Buena Elección
Para la mayoría de los casos, escribir datos en formato .csv es una opción confiable y ampliamente compatible.
Recomiendo usar la función
fwritedel paquetedata.tablepor su velocidad y eficiencia.
- A continuación, guardamos varios conjuntos de datos en la carpeta Intermediate usando fwrite:
# Escribir los Datos de IVA
fwrite(panel_vat, here("quarto_files", "Solutions", "Data", "Intermediate", "panel_vat.csv"))
# Escribir las Declaraciones de Impuesto de Sociedades
fwrite(panel_cit, here("quarto_files", "Solutions", "Data", "Intermediate", "panel_cit.csv"))
# Escribir las Características de Empresas
fwrite(dt_firms, here("quarto_files", "Solutions", "Data", "Intermediate", "dt_firms.csv"))Hay otras opciones para escribir datos
Escribiendo Archivos .rds (Para Objetos de R)
El formato .rds está específicamente diseñado para guardar objetos de R. Es útil para guardar resultados intermedios, objetos o datos.
Exploraremos este formato con más detalle más adelante, pero aquí hay un ejemplo rápido:
- Escribiendo Archivos .xlsx (Para Compatibilidad con Excel): Para guardar datos en formato Excel (.xlsx), usa el paquete writexl. Es ligero y no requiere dependencias externas.
- Escribiendo Archivos .parquet (Para Conjuntos de Datos Grandes): El formato .parquet es un formato de almacenamiento columnar que es altamente eficiente tanto para leer como para escribir grandes conjuntos de datos (típicamente >1GB).
Para Resumir
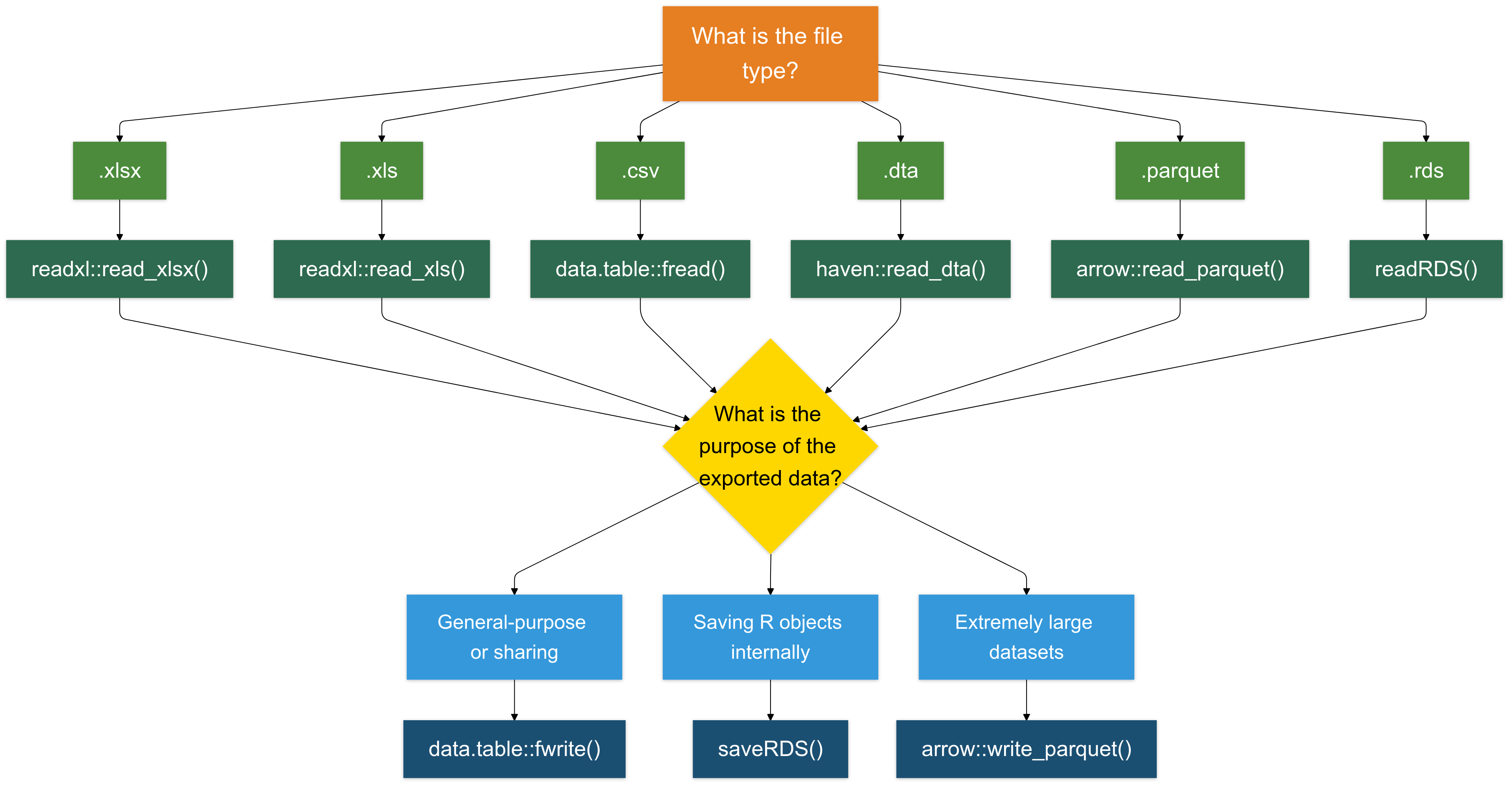
Ejercicio 3: Escribir Datos Limpios
Puedes encontrar el ejercicio en la carpeta “Exercises/exercise_03_template.R”
05:00 Tus tareas:
Guarda los tres conjuntos de datos limpios en diferentes formatos:
Características de empresas → CSV
Guardar comodata/intermediate/firms_clean.csvusandofwrite()Declaraciones de IVA → RDS
Guardar comodata/intermediate/vat_clean.rdsusandosaveRDS()Declaraciones de impuesto de sociedades → Parquet
Guardar comodata/intermediate/cit_clean.parquetusandowrite_parquet()Bonus: ¿Por qué elegimos diferentes formatos para cada conjunto de datos?
Ejercicio 3: Soluciones
# Cargar paquetes requeridos
library(data.table)
library(arrow)
library(here)
# Guardar características de empresas como CSV
fwrite(dt_firms, here("data", "intermediate", "firms_clean.csv"))
# Guardar declaraciones de IVA como RDS
saveRDS(panel_vat, here("data", "intermediate", "vat_clean.rds"))
# Guardar declaraciones de impuesto de sociedades como Parquet
write_parquet(panel_cit, here("data", "intermediate", "cit_clean.parquet"))
# Respuesta Bonus:
# dt_firms (CSV): Datos de referencia, legibles por humanos, compartidos entre departamentos
# panel_vat (RDS): Preserva tipos de datos de R, carga más rápida en flujos de trabajo de R
# panel_cit (Parquet): Almacenamiento columnar eficiente para grandes conjuntos de datos de panelBonus: Conectando R a Bases de Datos
- ¿Por Qué Conectar a Bases de Datos?
- Los datos a menudo se almacenan en bases de datos centralizadas para mayor seguridad, accesibilidad y gestión.
- Los flujos de trabajo tradicionales podrían implicar enviar solicitudes de datos a equipos de TI, causando retrasos y flexibilidad limitada para los analistas.
- El Poder de
Rpara Acceso a Bases de Datos
- Usando
R, puedes: - Consultar datos directamente y en tiempo real.
- Importar grandes conjuntos de datos sin problemas a tu entorno de
R.
Warning
Sin embargo, sugiero extraer los datos usando tu interfaz SQL y luego trabajar con los datos extraídos en R.
Ejemplo: conectando a una base de datos
# Cargar Paquetes
library(DBI) # este paquete siempre es necesario
library(RMariaDB) # hay paquetes para cada tipo de base de datos (ej. MySQL, PostgreSQL, etc.)
# Establecer una conexión a la base de datos
con <- dbConnect(
MariaDB(),
host = "database.server.com",
user = "tu_nombre_usuario",
password = "tu_contraseña",
dbname = "tax_database"
)
# Consultar la base de datos
tax_data <- dbGetQuery(con, "SELECT * FROM vat_declarations WHERE year = 2023")
# Desconectar cuando termines
dbDisconnect(con)