Transformación de Datos y Uniones
Capacitación en R
Introducción
El Desafío
Tu director entra:
“Necesitamos identificar las 5 principales empresas con las mayores brechas de IVA en el sector minorista. Divídelas por tamaño de empresa—pequeña, mediana y grande—basándose en el ingreso gravable anual de los datos de impuesto de sociedades. ¿Puedes tener esto listo para mañana?”
🤔 Piensas:
- Brecha de IVA = IVA esperado menos IVA pagado realmente
- Tengo datos de IVA trimestrales en columnas separadas
- El ingreso gravable viene de declaraciones de impuesto de sociedades (archivo diferente)
- Las características de la empresa (industria) están en otro archivo más
- ¡Necesito unir los tres conjuntos de datos!
Este módulo te enseña exactamente cómo resolver este problema.
Hoja de Ruta de Hoy
- Entender principios de datos ordenados (tidy)
- Transformar datos entre formatos ancho y largo
- Unir múltiples conjuntos de datos
- Validar que tus uniones funcionaron correctamente
- Construir un conjunto de datos completo listo para análisis
Resolviendo el Desafío: El Enfoque
¿Qué datos tenemos?
- Declaraciones de IVA trimestrales (formato ancho: columnas Q1, Q2, Q3, Q4)
- Declaraciones anuales de impuesto de sociedades (contiene ingreso gravable)
- Registro de empresas (industria, características de la empresa)
¿Qué necesitamos hacer?
- Transformar: Convertir IVA trimestral de formato ancho a largo
- Calcular: Totales anuales de IVA por empresa
- Unir: Combinar IVA con impuesto de sociedades para obtener ingreso gravable
- Categorizar: Definir tamaño de empresa basado en rangos de ingreso gravable
- Unir: Agregar características de empresa (industria)
- Filtrar y Clasificar: Seleccionar sector minorista, encontrar top 5 por categoría de tamaño
Pregunta clave: ¿Cómo pasamos de conjuntos de datos desordenados y separados a una tabla limpia de análisis?
Respuesta: ¡Dominando la transformación y las uniones!
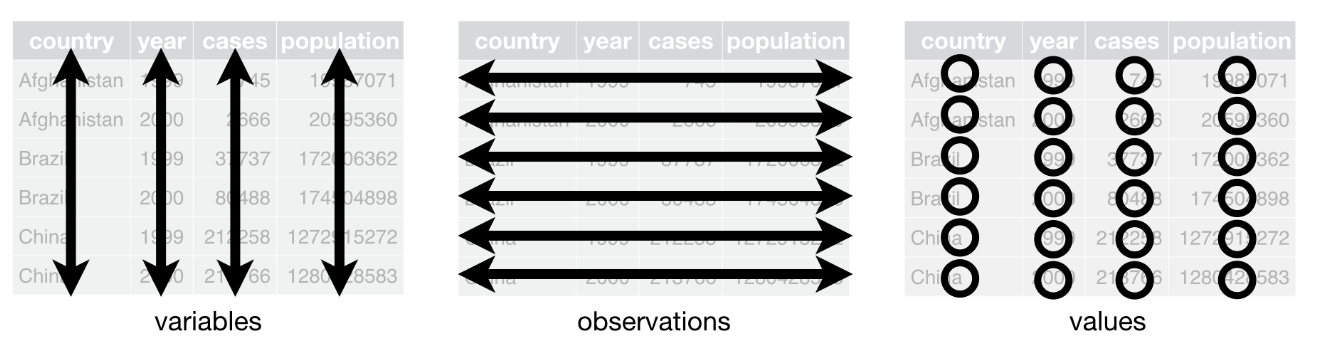
Datos Ordenados (Tidy)
Datos Administrativos Tributarios Ordenados
¿Qué son los Datos Ordenados?
Los datos ordenados organizan datos administrativos tributarios en un formato consistente y listo para análisis:
- Cada variable es una columna; cada columna es una variable.
- Cada observación es una fila; cada fila es una observación.
- Cada valor es una celda; cada celda es un solo valor.
Veamos Este Conjunto de Datos
| ID Contribuyente | Tipo Impuesto | 2021 Q1 | 2021 Q2 | 2021 Q3 | 2021 Q4 |
|---|---|---|---|---|---|
| 101 | Impuesto Renta | 500 | 600 | 450 | 700 |
| 102 | IVA | 300 | 400 | 350 | 500 |
¿Cuál es el problema con este conjunto de datos?
Problemas:
- La información de trimestre (Q1, Q2, Q3, Q4) está distribuida en nombres de columnas, no almacenada como datos
- Cada fila contiene múltiples observaciones (datos de 4 trimestres)
- Difícil filtrar por trimestres específicos o graficar tendencias en el tiempo
¿Cuáles son las variables?
ID Contribuyente, Tipo Impuesto, Trimestre, Monto Pago.
¿Qué constituye una sola observación en este conjunto de datos?
Una observación es un pago de impuesto específico para un contribuyente durante un trimestre particular.
Haciéndolo Ordenado
¿Cómo transformarías el conjunto de datos para cumplir las tres características ordenadas?
- Cada variable es una columna; cada columna es una variable.
- Cada observación es una fila; cada fila es una observación.
- Cada valor es una celda; cada celda es un solo valor.
Versión Ordenada
| ID Contribuyente | Tipo Impuesto | Trimestre | Monto Pago |
|---|---|---|---|
| 101 | Impuesto Renta | 2021 Q1 | 500 |
| 101 | Impuesto Renta | 2021 Q2 | 600 |
| 101 | Impuesto Renta | 2021 Q3 | 450 |
| 101 | Impuesto Renta | 2021 Q4 | 700 |
| 102 | IVA | 2021 Q1 | 300 |
| 102 | IVA | 2021 Q2 | 400 |
| 102 | IVA | 2021 Q3 | 350 |
| 102 | IVA | 2021 Q4 | 500 |
¿Por Qué Importa Esto?
Los datos ordenados facilitan el análisis:
- Calcular estadísticas por grupo (ej., pago promedio por trimestre)
- Crear visualizaciones con ggplot2
- Aplicar funciones consistentemente a través de observaciones
- Unir conjuntos de datos sin confusión
El Objetivo
La mayor parte de nuestro trabajo implica transformar datos desordenados en datos ordenados, luego analizarlos.
Parte 1: Entendiendo la Estructura de Datos
Unidad de Observación vs. Unidad de Análisis
Unidad de Observación
Lo que representa cada fila en tus datos brutos
- Presentación de IVA empresa-trimestre
- Declaración de impuesto de sociedades empresa-año
- Transacción individual
Unidad de Análisis
Lo que necesitas para tu análisis
- Tasa de cumplimiento empresa-año
- Tendencias a nivel industria
- Brecha tributaria agregada
Ejemplo: Tienes observaciones empresa-trimestre pero necesitas análisis empresa-año
- Observaciones: FIRM_001 tiene 4 filas (Q1, Q2, Q3, Q4 de 2023)
- Análisis: Quieres 1 fila por empresa-año con total anual
Formato Ancho vs. Largo
Formato Ancho
Cada período de tiempo es una columna
| firm_id | Q1_vat | Q2_vat | Q3_vat | Q4_vat |
|---|---|---|---|---|
| FIRM_01 | 1000 | 1200 | 1100 | 1300 |
| FIRM_02 | 800 | 900 | 950 | 1000 |
Bueno para:
- Calcular cambios período-a-período
- Tablas resumen
- Visualización estilo hoja de cálculo
Formato Largo
Cada observación es una fila
| firm_id | quarter | vat_amount |
|---|---|---|
| FIRM_01 | Q1 | 1000 |
| FIRM_01 | Q2 | 1200 |
| FIRM_01 | Q3 | 1100 |
| FIRM_01 | Q4 | 1300 |
| FIRM_02 | Q1 | 800 |
Bueno para:
- Gráficos de series temporales
- Operaciones group-by
- La mayoría de análisis estadísticos
Parte 2: Transformando Datos
¿Por Qué Pivot Longer?
Transformación más común en análisis de datos tributarios
Datos de IVA trimestrales anchos:
| firm_id | vat_q1 | vat_q2 | vat_q3 | vat_q4 |
|---|---|---|---|---|
| FIRM_01 | 5000 | 5200 | 4800 | 5500 |
↓ Transformar a largo ↓
| firm_id | quarter | vat_amount |
|---|---|---|
| FIRM_01 | Q1 | 5000 |
| FIRM_01 | Q2 | 5200 |
| FIRM_01 | Q3 | 4800 |
| FIRM_01 | Q4 | 5500 |
¿Por qué? Requerido para:
- Graficar tendencias temporales con ggplot2
- Calcular tasas de crecimiento trimestral
- Operaciones group-by (ej., promedio por trimestre)
- Cualquier análisis que trate el tiempo como variable
Sintaxis de pivot_longer()
Desglosándolo:
cols: Columnas a transformar (las que tienen mediciones repetidas)names_to: Nombre para la nueva columna que contendrá los nombres de columnas antiguasvalues_to: Nombre para la nueva columna que contendrá los valores
Piénsalo como “desempacar”
Estás tomando columnas (Q1, Q2, Q3, Q4) y desempacándolas en filas, almacenando el nombre de columna (Q1) y su valor (5000) por separado.
Ejemplo en Vivo: Pivot Longer
# Mostrar primero el formato ancho
head(vat_wide, 3)
# Transformar a formato largo
vat_long <- vat_wide %>%
pivot_longer(
cols = c(vat_q1, vat_q2, vat_q3, vat_q4),
names_to = "quarter",
values_to = "vat_amount"
)
# Mostrar el resultado
head(vat_long, 6)
# Verificar dimensiones
cat("Formato ancho:", nrow(vat_wide), "filas\n")
cat("Formato largo:", nrow(vat_long), "filas (¡4x más!)\n")🏋️♀️ Ejercicio 1: Práctica de Pivot Longer
Tarea: Transformar los datos de impuesto de sociedades anchos proporcionados a formato largo
- Abre
exercise_04_01_template.R - Carga los datos de CIT anchos desde
data/Intermediate/cit_wide.csv - Usa
pivot_longer()para transformar columnas de año a formato largo - Verifica que el resultado tenga 4x más filas
10:00 ¿Por Qué Pivot Wider?
Menos común, pero importante para tareas específicas
Datos en formato largo:
| firm_id | year | tax_type | amount |
|---|---|---|---|
| FIRM_01 | 2023 | VAT | 20000 |
| FIRM_01 | 2023 | CIT | 15000 |
| FIRM_02 | 2023 | VAT | 18000 |
| FIRM_02 | 2023 | CIT | 12000 |
↓ Transformar a ancho ↓
| firm_id | year | VAT | CIT |
|---|---|---|---|
| FIRM_01 | 2023 | 20000 | 15000 |
| FIRM_02 | 2023 | 18000 | 12000 |
¿Por qué? Útil para:
- Crear tablas resumen
- Calcular ratios (VAT/CIT)
- Comparaciones período-a-período
- Comparaciones lado a lado
Sintaxis de pivot_wider()
Desglosándolo:
id_cols: Columnas que identifican únicamente cada fila en el resultadonames_from: Qué columna contiene los valores que se convertirán en nuevos nombres de columnavalues_from: Qué columna contiene los valores para llenar las nuevas columnas
¡Cuidado con duplicados!
Si tienes múltiples filas con la misma combinación de id_cols y names_from, pivot_wider() creará una columna de lista. ¡Siempre verifica tus datos primero!
Ejemplo en Vivo: Pivot Wider
# Crear datos de muestra con IVA y CIT
tax_long <- tibble(
firm_id = rep(c("FIRM_01", "FIRM_02"), each = 2),
year = rep(2023, 4),
tax_type = rep(c("VAT", "CIT"), 2),
amount = c(20000, 15000, 18000, 12000)
)
# Mostrar formato largo
print(tax_long)
# Transformar a formato ancho
tax_wide <- tax_long %>%
pivot_wider(
id_cols = c(firm_id, year),
names_from = tax_type,
values_from = amount
)
# Mostrar resultado
print(tax_wide)
# Ahora podemos calcular fácilmente el ratio VAT/CIT
tax_wide <- tax_wide %>%
mutate(vat_cit_ratio = VAT / CIT)
print(tax_wide)Parte 3: Uniendo Datos
¿Por Qué Unir Datos?
En administración tributaria, los datos viven en sistemas separados:
Sistema IVA
- Declaraciones trimestrales
- IVA input/output
- Reembolsos
Sistema Impuesto Sociedades
- Declaraciones anuales
- Ingreso gravable
- Impuesto pagado
Registro Empresas
- Industria
- Tamaño
- Región
El Objetivo
Combinar estos conjuntos de datos para analizar el comportamiento de empresas a través de múltiples tipos de impuestos y características.
El Modelo de Datos Relacional
Tres tablas separadas vinculadas por firm_id:
Tabla 1: IVA (panel_vat)
| firm_id | quarter | vat_amount |
|---|---|---|
| FIRM_01 | Q1 | 5000 |
| FIRM_01 | Q2 | 5200 |
Tabla 2: Impuesto Sociedades (panel_cit)
| firm_id | year | cit_amount |
|---|---|---|
| FIRM_01 | 2023 | 15000 |
| FIRM_02 | 2023 | 12000 |
Tabla 3: Empresas (dt_firms)
| firm_id | industry | size |
|---|---|---|
| FIRM_01 | Retail | Medium |
| FIRM_02 | Services | Small |
La clave: firm_id aparece en las tres tablas, permitiéndonos vincularlas.
Claves de Unión: Cómo R Empareja Filas
Clave de unión = La(s) columna(s) usada(s) para emparejar filas entre tablas
Tabla A (IVA)
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Tabla B (Empresas)
| firm_id | industry |
|---|---|
| FIRM_01 | Retail |
| FIRM_02 | Services |
+
= ?
R empareja filas donde firm_id es el mismo
- FIRM_01 → Coincide ✓
- FIRM_02 → Coincide ✓
- FIRM_03 → No coincide ?
¿Qué pasa con FIRM_03?
¡Eso depende del tipo de unión!
Tipos de Uniones
left_join(): El Caballo de Batalla
Unión más usada (80% de casos del mundo real)
Mantiene todas las filas de la tabla izquierda
Tabla A (izquierda)
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Tabla B (derecha)
| firm_id | industry |
|---|---|
| FIRM_01 | Retail |
| FIRM_02 | Services |
Resultado: left_join(A, B)
| firm_id | vat | industry |
|---|---|---|
| FIRM_01 | 5000 | Retail |
| FIRM_02 | 4500 | Services |
| FIRM_03 | 6000 | NA |
Nota: FIRM_03 se mantiene, pero industry es NA
Por qué es la predeterminada
Preserva tu conjunto de datos primario (la tabla izquierda). Perfecto para enriquecer datos existentes con atributos adicionales.
left_join() en Acción
# Crear datos de muestra
vat_data <- tibble(
firm_id = c("FIRM_01", "FIRM_02", "FIRM_03"),
quarter = c("Q1", "Q1", "Q1"),
vat_amount = c(5000, 4500, 6000)
)
firm_data <- tibble(
firm_id = c("FIRM_01", "FIRM_02"),
industry = c("Retail", "Services"),
size = c("Medium", "Small")
)
# Mostrar tablas originales
cat("Datos de IVA:\n")
print(vat_data)
cat("\nDatos de empresa:\n")
print(firm_data)
# Realizar left join
vat_enriched <- left_join(vat_data, firm_data, by = "firm_id")
cat("\nDespués de left_join:\n")
print(vat_enriched)
# Verificar conteo de filas
cat("\nVerificación de conteo de filas:\n")
cat("Datos de IVA:", nrow(vat_data), "filas\n")
cat("Resultado:", nrow(vat_enriched), "filas (¡igual!)\n")🏋️♀️ Ejercicio 2: Tu Primera Unión
Tarea: Unir datos de CIT con características de empresa
- Abre
exercise_04_02_template.R - Carga
panel_cit.csvydt_firms.csv - Usa
left_join()para agregar características de empresa a datos de CIT - Verifica que el conteo de filas coincida con los datos de CIT
10:00 inner_join(): Solo Coincidencias
Mantiene solo filas que existen en AMBAS tablas
Tabla A
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Tabla B
| firm_id | industry |
|---|---|
| FIRM_01 | Retail |
| FIRM_02 | Services |
Resultado: inner_join(A, B)
| firm_id | vat | industry |
|---|---|---|
| FIRM_01 | 5000 | Retail |
| FIRM_02 | 4500 | Services |
Nota: FIRM_03 eliminada (sin coincidencia en Tabla B)
full_join(): Todo
Mantiene TODAS las filas de AMBAS tablas
Tabla A
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
Tabla B
| firm_id | cit |
|---|---|
| FIRM_02 | 12000 |
| FIRM_03 | 15000 |
Resultado: full_join(A, B)
| firm_id | vat | cit |
|---|---|---|
| FIRM_01 | 5000 | NA |
| FIRM_02 | 4500 | 12000 |
| FIRM_03 | NA | 15000 |
Nota: Todas las empresas mantenidas, con NAs donde no hay coincidencia
anti_join(): La Herramienta Detective
Retorna filas de la tabla izquierda que NO tienen coincidencia en la tabla derecha
Tabla A (Presentadores IVA)
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Tabla B (Presentadores CIT)
| firm_id | cit |
|---|---|
| FIRM_01 | 15000 |
| FIRM_02 | 12000 |
Resultado: anti_join(A, B)
| firm_id | vat |
|---|---|
| FIRM_03 | 6000 |
Nota: Solo FIRM_03 retornada (presentó IVA pero no CIT)
¡Crítico para diagnósticos!
Usa anti_join() para encontrar:
- Empresas que presentaron IVA pero no CIT
- Registros que no se unieron (problemas de calidad de datos)
- Valores faltantes en tablas de búsqueda
Comparación Visual: Los Cuatro Tipos de Unión
Mismos Datos de Ejemplo, Diferentes Tipos de Unión:
Tabla A (IVA)
| firm_id | vat |
|---|---|
| FIRM_01 | 5000 |
| FIRM_02 | 4500 |
| FIRM_03 | 6000 |
Tabla B (CIT)
| firm_id | cit |
|---|---|
| FIRM_01 | 15000 |
| FIRM_02 | 12000 |
| FIRM_04 | 18000 |
Comparación Visual: Resultados
left_join(A, B)
| firm_id | vat | cit |
|---|---|---|
| FIRM_01 | 5000 | 15000 |
| FIRM_02 | 4500 | 12000 |
| FIRM_03 | 6000 | NA |
Filas: 3 (todas de A)
inner_join(A, B)
| firm_id | vat | cit |
|---|---|---|
| FIRM_01 | 5000 | 15000 |
| FIRM_02 | 4500 | 12000 |
Filas: 2 (solo coincidencias)
full_join(A, B)
| firm_id | vat | cit |
|---|---|---|
| FIRM_01 | 5000 | 15000 |
| FIRM_02 | 4500 | 12000 |
| FIRM_03 | 6000 | NA |
| FIRM_04 | NA | 18000 |
Filas: 4 (todas de ambas)
anti_join(A, B)
| firm_id | vat |
|---|---|
| FIRM_03 | 6000 |
Filas: 1 (en A, no en B)
Mejores Prácticas de Unión
Uniones con Múltiples Claves
A veces una clave no es suficiente
Problema: La misma empresa aparece en múltiples años
Datos de IVA (panel)
| firm_id | year | quarter | vat |
|---|---|---|---|
| FIRM_01 | 2022 | Q1 | 5000 |
| FIRM_01 | 2023 | Q1 | 5200 |
Características de empresa (también panel)
| firm_id | year | industry |
|---|---|---|
| FIRM_01 | 2022 | Retail |
| FIRM_01 | 2023 | Retail |
¡Si unes solo por firm_id, obtendrás coincidencias duplicadas!
Nombres de Columna Diferentes
Los datos reales a menudo tienen nomenclatura inconsistente
Tabla A usa ‘id’
| id | vat |
|---|---|
| FIRM_01 | 5000 |
Tabla B usa ‘firm_id’
| firm_id | industry |
|---|---|
| FIRM_01 | Retail |
Parte 4: Validando Uniones
Por Qué Importa la Validación
⚠️ Historia de Horror
Ejecutas una unión. Todo parece bien. Envías resultados a tu director.
😱 Al día siguiente:
“Estos números parecen incorrectos. ¿Por qué tenemos 50,000 observaciones empresa-año cuando solo tenemos 5,000 empresas?”
¿Qué pasó? Claves duplicadas en la tabla derecha causaron una explosión de filas.
Lección: Confía, pero verifica. SIEMPRE valida tus uniones.
Problemas Comunes de Unión
- Claves duplicadas → Explosión de filas
- La tabla derecha tiene múltiples filas por clave
- Resultado: Más filas de las que comenzaste
- Claves faltantes → NAs no deseados
- Las claves no coinciden entre tablas
- Resultado: Muchos valores faltantes
- Desajustes de tipo de datos → Cero coincidencias
- Una tabla tiene IDs numéricos, la otra tiene IDs de carácter
- Resultado: No coinciden filas en absoluto
- Errores tipográficos en nombres de columna de unión
- Escribiste
by = "firm_id"pero una tabla usa"firm_ID" - Resultado: Error o unión cartesiana
- Escribiste
Lista de Verificación Diagnóstica
ANTES de unir:
# 1. Verificar claves duplicadas en ambas tablas
panel_vat %>%
count(firm_id, year) %>%
filter(n > 1)
dt_firms %>%
count(firm_id, year) %>%
filter(n > 1)
# 2. Verificar que columnas clave existan y tengan el mismo tipo
str(panel_vat$firm_id)
str(dt_firms$firm_id)
# 3. Verificar valores faltantes en columnas clave
sum(is.na(panel_vat$firm_id))
sum(is.na(dt_firms$firm_id))Lista de Verificación Diagnóstica (cont.)
DESPUÉS de unir:
# 4. Verificar conteo de filas - ¿tiene sentido?
cat("Antes de unir:", nrow(panel_vat), "filas\n")
cat("Después de unir:", nrow(merged_data), "filas\n")
# Para left_join, debería coincidir con tabla izquierda (a menos que derecha tenga duplicados)
# Para inner_join, debería ser menor o igual a cualquier tabla
# 5. Encontrar no-coincidencias usando anti_join
unmatched <- anti_join(panel_vat, dt_firms, by = c("firm_id", "year"))
cat("Filas sin coincidencia:", nrow(unmatched), "\n")
# 6. Verificar NAs inesperados en columnas unidas
merged_data %>%
summarize(
na_industry = sum(is.na(industry)),
na_size = sum(is.na(size))
)
# 7. Verificación puntual de algunas filas
merged_data %>%
filter(firm_id == "FIRM_001") %>%
select(firm_id, year, vat_amount, industry, size)🏋️♀️ Ejercicio 3: Diagnosticar y Reparar
Tarea: La unión proporcionada produce el número incorrecto de filas. Encuentra y repara el problema.
- Abre
exercise_04_03_template.R - Ejecuta el código de unión roto
- Usa herramientas de diagnóstico para identificar el problema
- Repara la unión y valida el resultado
15:00 Parte 5: Flujo de Trabajo Completo
Juntando Todo
Escenario Realista: Calculando Brecha de IVA por Tamaño de Empresa
Tu director quiere identificar las 5 principales empresas con mayores brechas de IVA en minorista, segmentadas por tamaño.
El Pipeline:
- Transformar: Convertir datos de IVA trimestrales de formato ancho a largo
- Agregar: Calcular totales anuales de IVA por empresa
- Agregar: Calcular ingreso gravable anual de datos de CIT
- Unir: Combinar IVA con datos de CIT para obtener ingreso gravable
- Unir: Agregar características de empresa (industria)
- Categorizar: Crear categorías de tamaño de empresa basadas en ingreso gravable
- Pequeña: Ingreso Gravable < $50K
- Mediana: $50K ≤ Ingreso Gravable < $125K
- Grande: Ingreso Gravable ≥ $125K
- Calcular: Brecha de IVA = IVA Esperado - IVA Pagado Real
- Filtrar y Clasificar: Seleccionar industria minorista, encontrar top 5 por categoría de tamaño
- Validar: Verificar que los resultados tengan sentido
Codificación en Vivo: Pipeline Completo
# Paso 1: Transformar IVA de ancho a largo (si es necesario)
# En este ejemplo, panel_vat ya está en formato largo, así que agregaremos directamente
# Paso 2: Agregar IVA a nivel empresa-año
vat_annual <- panel_vat %>%
mutate(year = lubridate::year(declaration_date)) %>%
group_by(firm_id, year) %>%
summarize(
actual_vat = sum(vat_outputs - vat_inputs, na.rm = TRUE),
vat_inputs = sum(vat_inputs, na.rm = TRUE),
vat_outputs = sum(vat_outputs, na.rm = TRUE),
quarters_filed = n(),
.groups = "drop"
)
# Paso 3: Agregar CIT para obtener ingreso gravable
cit_annual <- panel_cit %>%
mutate(year = lubridate::year(declaration_date)) %>%
group_by(firm_id, year) %>%
summarize(
taxable_income = sum(taxable_income, na.rm = TRUE),
.groups = "drop"
)
# Paso 4: Unir IVA con datos de CIT
vat_cit <- left_join(
vat_annual,
cit_annual,
by = c("firm_id", "year")
)
# Paso 5: Unir con características de empresa
vat_with_firms <- left_join(
vat_cit,
dt_firms,
by = c("firm_id", "year")
)
# Paso 6: Crear categorías de tamaño basadas en ingreso gravable
vat_with_firms <- vat_with_firms %>%
mutate(
firm_size = case_when(
taxable_income < 50000 ~ "Pequeña",
taxable_income >= 50000 & taxable_income < 125000 ~ "Mediana",
taxable_income >= 125000 ~ "Grande",
is.na(taxable_income) ~ "Desconocido",
TRUE ~ "Desconocido"
)
)
# Paso 7: Calcular brecha de IVA (ejemplo simplificado)
# Brecha de IVA = IVA Esperado - IVA Real
vat_analysis <- vat_with_firms %>%
mutate(
expected_vat = vat_outputs * 0.15, # Asumiendo tasa de IVA del 15%
vat_gap = expected_vat - actual_vat
)
# Paso 8: Filtrar a minorista y encontrar top 5 por tamaño
top_gaps <- vat_analysis %>%
filter(industry == "Retail", !is.na(vat_gap)) %>%
group_by(firm_size) %>%
slice_max(order_by = vat_gap, n = 5) %>%
ungroup()
# Paso 9: Validar
cat("Resumen del análisis:\n")
cat("Total de empresas analizadas:", nrow(vat_analysis), "\n")
cat("Empresas minoristas:", sum(vat_analysis$industry == "Retail", na.rm = TRUE), "\n")
cat("Brechas principales por tamaño:\n")
print(top_gaps %>% count(firm_size))
# Guardar resultados
fwrite(
vat_analysis,
here("data", "final", "vat_gap_analysis.csv")
)
cat("\n✓ ¡Análisis de brecha de IVA completo!\n")🏋️♀️ EJERCICIO FINAL: Análisis de Brecha de IVA
Tarea: Identificar las 5 principales empresas minoristas con mayores brechas de IVA, por categoría de tamaño
- Abre
exercise_04_final_template.R - Sigue los pasos estructurados para:
- Transformar datos de IVA anchos a formato largo
- Calcular totales anuales de IVA por empresa
- Crear categorías de tamaño basadas en ingreso gravable
- Unir datos de IVA con características de empresa
- Calcular brecha de IVA para cada empresa
- Filtrar a industria minorista
- Encontrar las 5 principales empresas por categoría de tamaño
- Guardar resultados en
data/Final/vat_gap_analysis.csv
¡Este análisis ayudará a identificar riesgos de cumplimiento por tamaño de empresa!
20:00 Resumen
Conclusiones Clave
- Los datos ordenados siguen tres principios
- Cada variable es una columna
- Cada observación es una fila
- Cada valor es una celda
- Usa
pivot_longer()para la mayoría de tareas de transformación- Ancho a largo es la transformación más común
- Usa
left_join()como tu unión predeterminada- Preserva tu conjunto de datos primario
- Más común en la práctica (80% de casos)
- Siempre valida tus uniones antes de proceder
- Verifica conteos de filas
- Busca NAs inesperados
- Usa
anti_join()para encontrar no-coincidencias
- Sigue un flujo de trabajo diagnóstico:
- Verificar claves → Unir → Verificar → Analizar
Recursos
📖 Lectura Adicional
R4DS Capítulo 6: Ordenamiento de datos
https://r4ds.hadley.nz/data-tidyR4DS Capítulo 20: Uniones
https://r4ds.hadley.nz/joinsHoja de referencia dplyr: Referencia de funciones de unión
Hoja de referencia tidyr: Referencia de funciones pivot
¡Excelente Trabajo!
🎉 Ahora puedes:
- Entender y aplicar principios de datos ordenados
- Transformar datos entre formatos ancho y largo
- Combinar múltiples conjuntos de datos usando uniones
- Validar tus uniones para detectar problemas
- Construir conjuntos de datos listos para análisis
¡Has resuelto el desafío!
Ahora sabes cómo: - Transformar datos trimestrales a anuales - Unir características de empresas - Calcular métricas como brecha de IVA - Segmentar por categorías (tamaño de empresa, industria) - Clasificar e identificar principales desempeños/riesgos
La práctica hace al maestro
La mejor manera de dominar las uniones es practicar con datos reales. ¡No dudes en experimentar con diferentes tipos de uniones y ver qué sucede!